Partnering with the roleplay community we collected 6.2M dialogues in a 2-week A/B test. This allowed us to evaluate Higgs v2 directly against other models. Compared to Claude 3.5 Sonnet, Higgs v2 reduces the response regeneration rate(1) by 21.6%. This rate matters as it directly relates to the cases where users are unhappy with the generated result. Moreover, it increases the day 1 retention rate(2) by 5.3%.
Higgs Judger
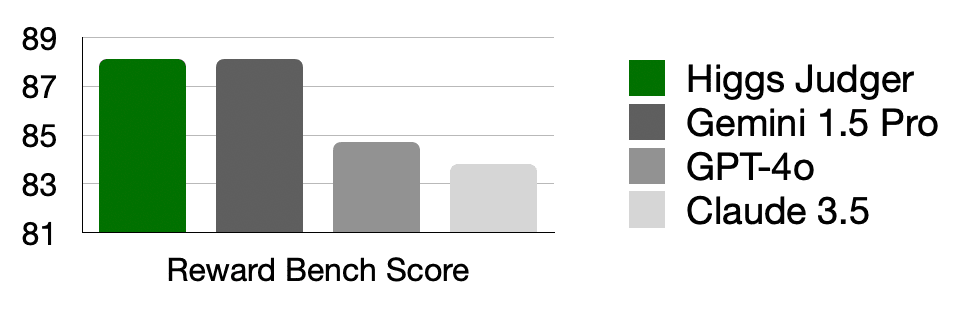
Much of the performance boost of Higgs v2 comes from an improved judging system, which guides the model alignment through synthetic feedback signals. We built an in-house LLM reward model, named Higgs Judger, to evaluate model outputs. On Reward Bench, Higgs Judger ties with the best generative judger, Google’s Gemini 1.5 Pro, in the leaderboard.
In addition, this judger model learns the preference of players during roleplays, using the the feedback that the user provides.
Performance on Reward Bench
| Model | Reward Bench score |
|---|---|
| Higgs Judger | 88.1 |
| Gemini 1.5 Pro (05/14) | 88.1 |
| GPT-4 Turbo (04/09) | 85.1 |
| GPT-4o | 84.7 |
| Claude 3.5 Sonnet | 83.8 |
| Claude 3 Opus | 80.7 |
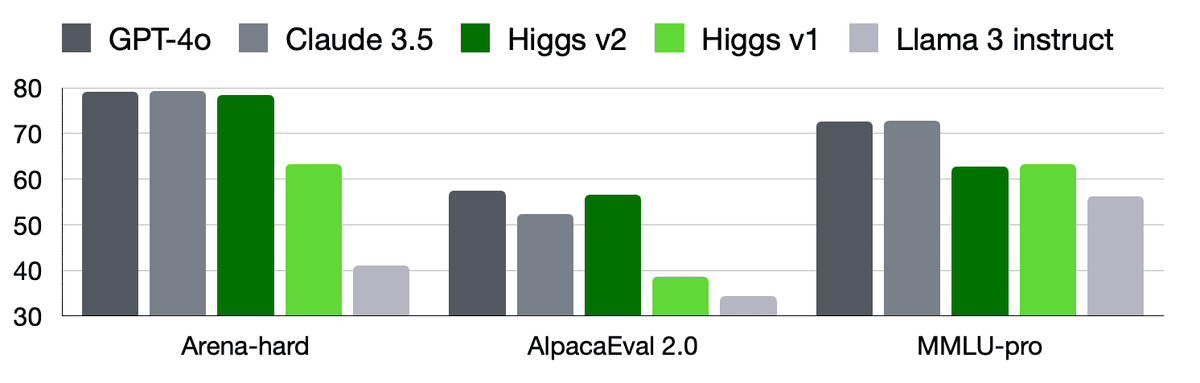
Performance on Arena-Hard
| Model | Arena-Hard |
|---|---|
| Claude 3.5 Sonnet | 79.3 |
| GPT-4o | 79.2 |
| Higgs Llama 3 70B v2 | 78.6 |
| GPT-4 Turbo (01/25) | 78.0 |
| Gemini 1.5 Pro | 72.0 |
| Claude 3 Opus | 60.4 |
| Higgs Llama 3 70B 3 | 49.6 |
| Claude 3 Sonnet | 46.8 |
| Llama 3 70B Instruct | 41.1 |
| Mistral Large | 37.7 |
Performance on AlpacaEval 2.0
| Model | AlpacaEval 2.0 |
|---|---|
| GPT-4o | 57.5 |
| Higgs Llama 3 70B v2 | 56.7 |
| GPT-4 Turbo (04/09) | 55.0 |
| Claude 3.5 Sonnet | 52.4 |
| Claude 3 Opus | 40.5 |
| Higgs Llama 3 70B | 38.6 |
| Claude 3 Sonnet | 34.9 |
| Llama 3 70B Instruct | 34.4 |
| Mistral Large | 32.7 |
Performance on MMLU Pro
| Model | MMLU-Pro |
|---|---|
| GPT-4o | 72.6 |
| Gemini 1.5 Pro | 69.0 |
| Claude 3 Opus | 68.5 |
| GPT-4 Turbo | 63.7 |
| Higgs Llama 3 70B | 63.2 |
| Higgs Llama 3 70B v2 | 62.8 |
| Gemini 1.5 Flash | 59.1 |
| Claude 3 Sonnet | 56.8 |
| Llama 3 70B Instruct | 56.2 |
Acknowledgments
Model: Xingjian Shi, Rand Xie, Weisu Yin
Serving: Yizhi Liu, Zach Zheng
Data / Evaluation: Yi Zhu, Jaewon Lee, Weisu Yin, Canwen Xu
Training Infrastructure: Shuai Zheng, Rand Xie
Hardware: Sergii Tiugaiev, Kells Kearney, Alex Shylo
We would like to thank our customers for their constructive feedback and the excellent technical support from our friends at NVIDIA, Arc Compute, eStruxture, Crusoe, AWS and Scaleway.