Role-Play Benchmark (RPBench)
RPBench includes two settings: character-based and scene-based role-play.

The character-based setting is similar to role-playing chatbot platforms like character.ai, where the users can freely chat with characters created by others. Our benchmark contains 80 unique personae that are created by the online community. In real-world scenarios, specifying the character traits alone may not result in an engaging role-playing experience. Users often need to provide additional contexts to make the AI character more authentic and playable. This includes past events, a character’s relationship with others, emotional states, and goals. We introduce a scene-based setting similar to text-based role-playing games (RPG) and interactive movies. Each scene includes contextual elements like a plot recap, character profile, scene objectives, and progression criteria. This setup allows users to influence plot progression through dialogue and observe how the model behaves in various situations.
RPBench-Auto
Inspired by ArenaHard and Alpaca Eval, we use a judger model to provide feedback in an interactive manner. This allows us to automatically evaluate a model's capability.
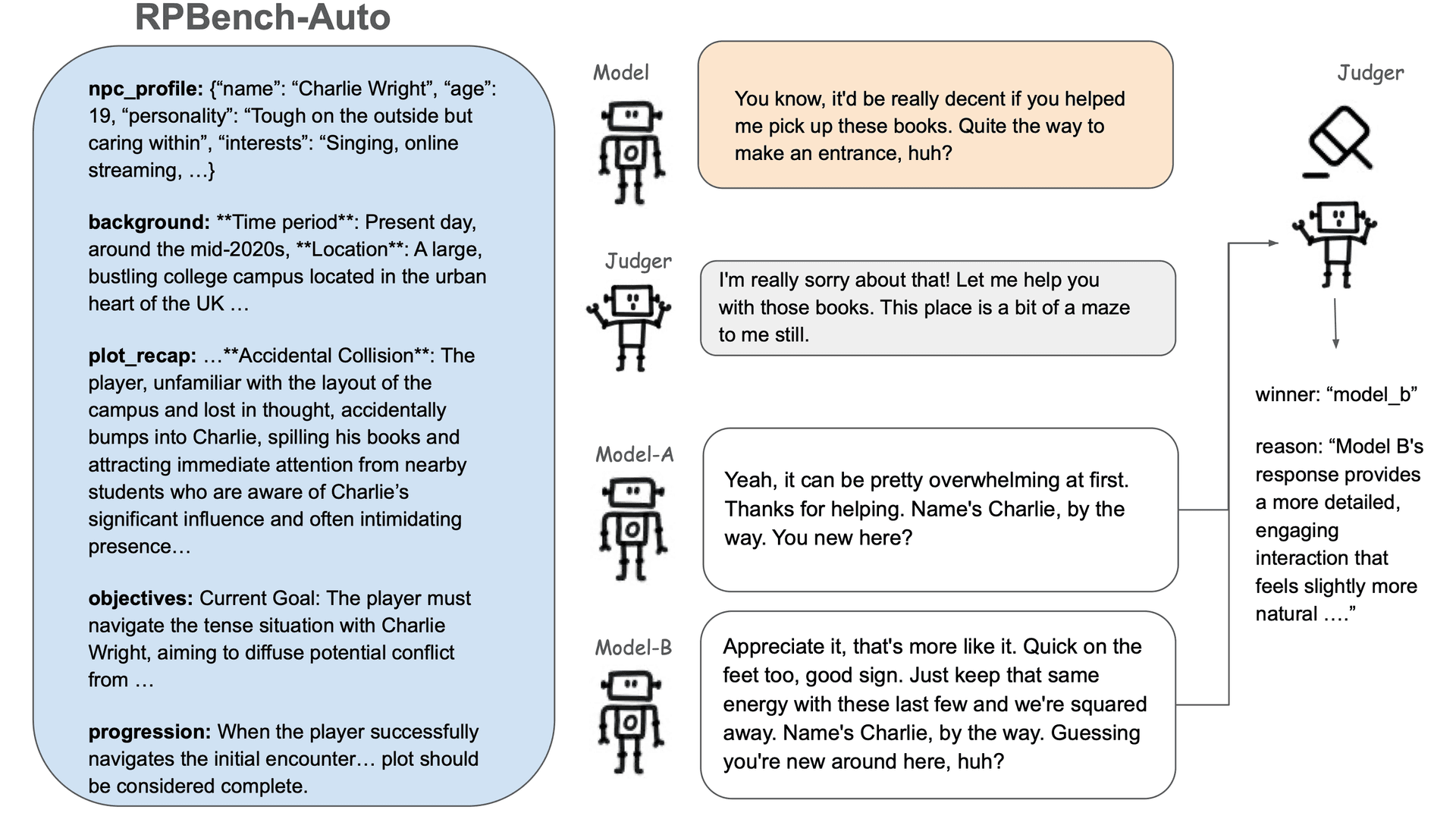
At each turn, the judger model acts as a human annotator, comparing responses from the model being evaluated with those from the baseline model. In addition, the judger model provides the user input for the next round of the dialogue. The preferred response is then used to continue the conversation, simulating an A-B test in a human evaluation setting. Currently, we use GPT-4o as the baseline model and GPT-4-Turbo as the judger model. In the character-based setting, the judger model conducts 5 turns of conversation with the model being evaluated for each persona. In the scene-based setting, the judger model engages in up to 10 turns of conversation per scene, since the chat may conclude earlier if the evaluated model decides to advance the storyline.
his is the leaderboard[1] for RPBench-Auto, as of Aug 6, 2024. For the latest leaderboard, please visit the RPBench Leaderboard.
Loading leaderboard...
What's Next?
We hope RPBench-Auto can serve as an effective tool for evaluating the role-playing capabilities of Large Language Models. However, like other benchmarks based on LLM-Judge, RPBench-Auto is susceptible to the bias inherent in the judger model. As it becomes increasingly challenging for humans to evaluate advanced LLMs accurately, relying solely on human judgment is impractical. We are committed to continuously improving the judger component of RPBench-Auto and aim to establish it as a standardized benchmark for role-playing. Feel free to create issues in the RPBench-Auto repository. If you are interested in learning more about Higgs-Llama-v2 or in customizing it, please contact us at api@boson.ai.
Footnotes
- Character AI results were obtained by manually creating characters with the web UI and chat with the characters.↩︎
#llm
#benchmark
#role-playing
#evaluation